![[포토샵 라이트룸 강의 리부트] #4 디지털 사진의 첫걸음, 히스토그램에 대해서 알아 보자](https://i.ytimg.com/vi/5i-u5TOTlbY/hqdefault.jpg)
콘텐츠
이 기사에서 : 히스토그램 읽기
통계를 연구하거나 기술 데이터를 수집하는 문서를 참조해야하는 경우 포함 된 히스토그램도 읽을 수 있어야합니다. 히스토그램은 정보를 시각적으로 표현할 수있는 도구입니다. 일반적으로 그룹 또는 샘플 내에서 현상 발생 횟수를 나타내는 막대가 서로 붙어있는 그래프입니다. 신 생물에있어서, 일부 기본 적응증은 히스토그램에 넣을 수있는 것과 그것이 어떻게 해석되어야 하는지를 이해하기에 충분할 것입니다.
단계
1 부 히스토그램 읽기
-
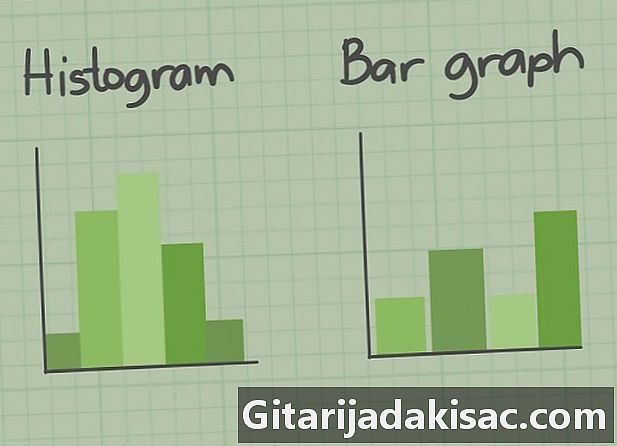
그것들을 인식하는 법을 배우십시오. 모양이 비슷하지만 특성이 매우 다른 막 대형 차트와 구분해야합니다. 막대 차트를 사용하면 숫자를 범주로 그룹화 할 수 있으며 히스토그램은 다른 범위의 숫자 분포를 보여줍니다. 일반적으로 히스토그램은 크기, 무게, 시간 등과 같은 일련의 연속 변수를 나타내는 데 사용됩니다.- 막대 차트에는 서로 다른 막대 사이에 공백이 있으며 막대 그래프에는 해당되지 않습니다.
- 히스토그램은 종종 정의 된 간격으로 이벤트 빈도를 상징하는 데 사용됩니다. 이벤트가 발생한 횟수를 보여줍니다.
-
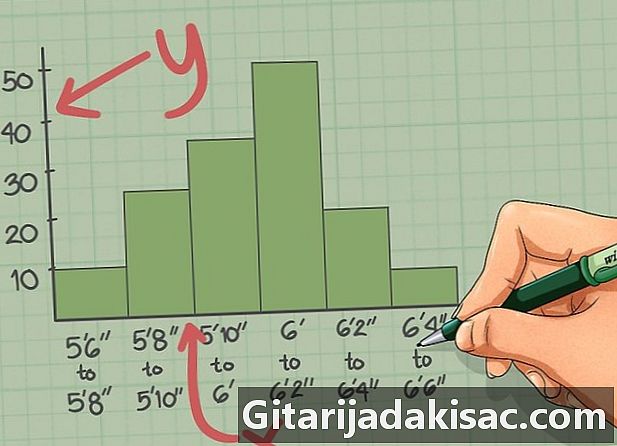
차트 축을 읽습니다. 가로축을 엑스 세로축 그곳에. 둘 다 잘 이해하는 데 필수적입니다. 히스토그램이 이벤트의 빈도를 표시하는 경우가 종종 있으므로이 빈도는 그곳에. 축 엑스 데이터가 그룹화 된 간격을 나타내는 데 사용됩니다.- 예를 들어, 다양한 크기의 프로 야구 투수의 빈도를 나열한 히스토그램에서 엑스 축의 주파수 그곳에.
-
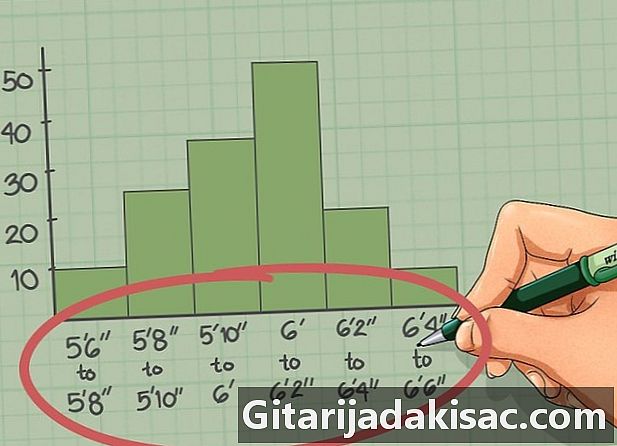
수업을 확인하십시오. 형식을 지정하기 위해 데이터는 클래스로 그룹화됩니다.히스토그램을 만들 때 결과를 올바르게 해석 할 수 있도록 올바른 클래스를 선택하는 것이 중요합니다. 너무 넓거나 제한적이지 않은 범위를 선택하십시오. 분석 된 데이터의 발생 빈도에 기본 패턴이 나타나야합니다.- 예를 들어, 프로 야구 투수의 평균 크기는 1.88m입니다. 물론 예외도 있습니다. 나열되는 크기의 범위는 아마도 1.68m에서 1.98m 사이이며 클래스는 4에서 5cm까지 다양합니다.
- 또한 1 등석이 1.68m에서 1.73m이면 키가 1.73m 인 선수는 포함되지 않습니다. 각 클래스에는 다음 클래스의 첫 번째 값을 제외하고 일치하는 값이 포함됩니다.
-
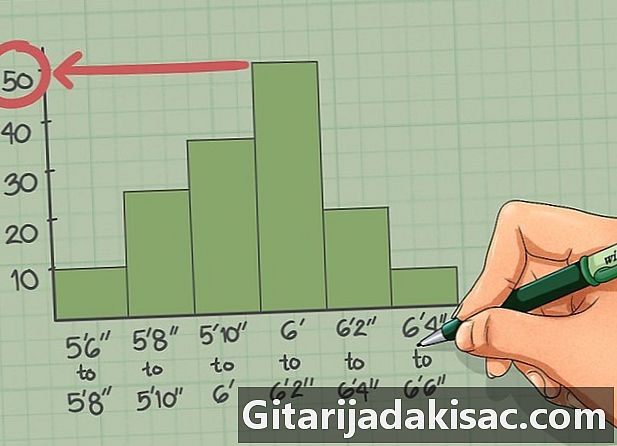
이 그룹의 빈도를 읽으십시오. 특정 간격으로 이벤트가 몇 번이나 발생했는지 확인하려면 막대 위로 얼마나 멀리 있는지 확인하고 엑스 이 수준에 어떤 가치가 있는지 알기 위해.- 예를 들어, 히스토그램에서 크기가 1.83m 이상이고 엄격하게 1.88m 미만인 플레이어의 수는 50 인 것을 읽을 수 있습니다.
2 부 히스토그램 그리기
-

데이터를 수집하십시오. 무언가의 빈도에 대한 정보를 찾고 있다면, 그것들을 한눈에 볼 수있는 좋은 방법입니다. 히스토그램은 서점의 판매량 또는 농장의 가축 무게에 관계없이 데이터 분포에 대한 일반적인 아이디어를 얻는 가장 실용적인 방법입니다. . -

간격을 선택하십시오. 데이터를 어디에 두어야하는지 알기 위해서는 먼저 데이터를 클래스로 나누는 방법을 결정해야합니다. 선택한 수업은 현실을 대표해야하므로 너무 크거나 제한적이어서는 안됩니다.- 예를 들어, 농장의 젖소 무게와 관련하여 520, 630, 500, 730, 820, 700, 790, 610, 630 및 590 kg의 10 가지 결과가 있다고 가정 해보십시오. 동물의 무게는 수백 킬로그램에서 다양하므로 수업 시간과 동일합니다.
- 500에서 시작하여 900까지 100kg마다 새로운 클래스를 만듭니다.
- 500-600, 600-700, 700-800 및 800-900의 총 4 가지 수업이 있습니다.
-

데이터를 분배하십시오. 네 개의 클래스가 만들어지면 데이터를 주문하고 그 안에 저장하면됩니다. 값을 오름차순으로 정렬하여 시작하십시오. 그런 다음 수업 분리 레벨에서 마커를 그립니다. 각각에있는 값을 세십시오. 얻은 결과는 각 간격의 빈도입니다.- 값이 클래스의 상한과 같으면 다음 클래스로 넘어갑니다.
- 예를 들어 농장의 젖소의 무게에 해당하는 10 가지 값 (520, 630, 500, 730, 820, 700, 790, 610, 630, 590)을 예로 들어 보겠습니다.
- 500, 520, 590, 610, 630, 630, 700, 730, 790 및 820으로 오름차순으로 분류합시다.
- 이 값을 500, 520, 590 | 610, 630, 630 | 700, 730, 790 | 820 클래스로 나눕니다.
- 주파수를 세어 봅시다 : 클래스 1 : 3, 클래스 2 : 3, 클래스 3 : 3, 클래스 4 : 1.
-
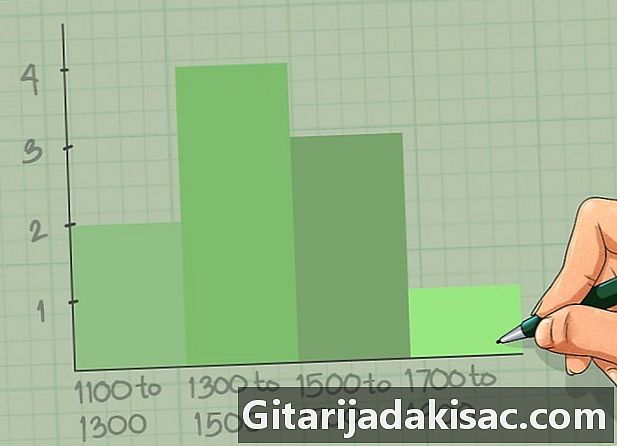
히스토그램을 그립니다. 획득 한 데이터에서 직접 히스토그램을 그리거나 Excel 또는 기타 통계 소프트웨어를 사용할 수 있습니다. 한 장의 용지에서 작업하는 경우 직각이 아닌 마크를 그리고 스케일을 설정하여 시작하십시오. 엑스 그리고 축 그곳에. 이전에 선택한 수업을 가로 좌표에 넣습니다. 축의 스케일 그곳에 클래스와 관련된 값의 빈도에 의해 결정됩니다. 마지막으로 히스토그램의 색상을 지정하고 다른 막대가 서로 닿도록하십시오.- 소의 무게, 예의 축 엑스 500에서 900까지의 범위에서 100 씩 증가합니다. 그곳에 1에서 4로 증가하여 1 씩 증가합니다.
- 첫 번째 클래스에서는 500에서 600까지 3 개의 값이 있으므로 첫 번째 막대는 3까지 올라갑니다. 이 높이까지 채색하십시오. 바로 옆에 다음 두 클래스의 빈도도 3입니다. 마지막으로 마지막 막대는 숫자 1 만가집니다.
-
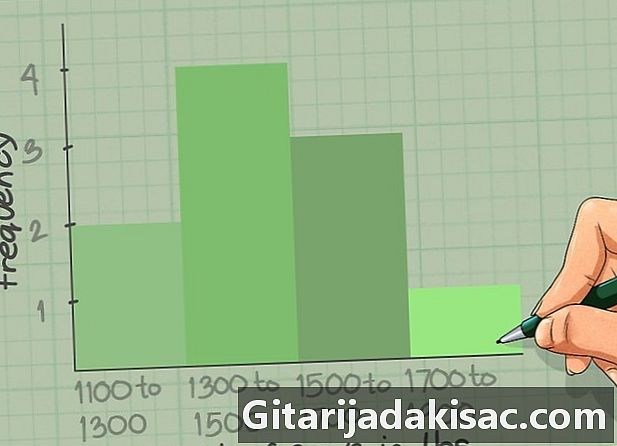
축을 잠그십시오. 각 축이 무엇인지 말할 때까지 히스토그램이 의미가 없습니다. 범례가 읽기 쉽도록 크게 작성하고 선택한 단어가 표현 된 데이터와 완벽하게 일치하는지 확인하십시오. 축 그곳에 "빈도"라고 불리며 엑스 작업 한 데이터의 특성에 따라 다릅니다.- 우리의 경우 엑스 "킬로그램에있는 암소의 무게"와 그곳에 "주파수".